投稿日
2013/3/26 火曜日
本格的にGPGPUをはじめざるを得ない可能性が個人的に高まってきたのでメモ。
いちばん簡単なんてタイトル付けてるけど実は他のやり方をあまり調べてないので、もっといい方法があれば教えてください。
CUDAには大きく分けてCUDA Runtime APIを使う方法と、CUDA Driver APIを使う方法がある。
どちらもデバイスコードの書き方は同じだが、ホストコードの書き方が違う。
Runtime APIが上位、Driver APIが下位なので、コードを書くのは前者の方が短くて済む。
しかし今回はDriver APIを使う方法を書いていく。
Driver APIのほうがかゆい所に手が届くし、デバイスコードとホストコードを分離出来るし、多分実際のアプリではDriver APIを使う人が過半数なのではないかと思う。
それに何よりDriver APIだと普通のコンパイラでホストコードがコンパイル可能だが、Runtime APIだとホストコードもnvcc(CUDA コンパイラ)を通さなきゃ行けなくて、これがXcodeと相性が悪く設定が面倒なのだ。
ちなみに、ホストコードの書き方をググったとき、それがRuntime APIのものかDriver APIのものか明記されてない場合が多いが、関数の接頭辞がRuntime APIの場合はcuda、Driver APIの場合はcuになってるのですぐ見分けがつく。
https://developer.nvidia.com/cuda-downloads
今回は、 cuda_5.0.36_macos-2.pkg をダウンロードしてフルインストールした。
古いバージョンがすでにインストールされてても自動的にいい感じにしてくれるみたい。
多分今回は必須じゃないがインストールが終わったら~/.bash_profileとかでCUDA用の環境変数を設定しとくと後々楽かもしれない。
export PATH=/Developer/NVIDIA/CUDA-5.0/bin:$PATH export DYLD_LIBRARY_PATH=/Developer/NVIDIA/CUDA-5.0/lib:$DYLD_LIBRARY_PATH
詳しいインストール方法はこちらを参照。
http://docs.nvidia.com/cuda/cuda-getting-started-guide-for-mac-os-x/index.html
OS X → Application → Command Line Tool を選択。
Driver APIを使うので多分言語はCでもC++でもObjective-C+Cocoaでもいいと思うが今回はCにした。
プロジェクト名はCUDATestとした。
フレームワークが /Library/Frameworks/CUDA.framework にあるので TERGETS → Build Phases → Link Binary With Libraries にて追加。
あと、 PROJECT → Build Settings → Search Paths → Framework Search Paths に /Library/Frameworks をセット。
kernel.cu というファイルを新規追加しコードを書く。
今回はテストということで以下のようにデータをインクリメントするだけの簡単なカーネルを書いた。
(ただしインデクシングだけはグリッド、ブロックの最多次元対応という)
extern "C"
{
__global__ void addone(float *v, int n)
{
int blockIndex = gridDim.x * blockIdx.y + blockIdx.x;
int threadPerBlock = blockDim.x * blockDim.y * blockDim.z;
int threadIndex = blockIndex * threadPerBlock
+ blockDim.x * blockDim.y * threadIdx.z
+ blockDim.x * threadIdx.y
+ threadIdx.x;
if (threadIndex < n) {
v[threadIndex] = v[threadIndex] + 1.0f;
}
}
}
extern “C” {}で囲まない場合、このコードをコンパイルすると関数名(エントリポイント名)がname manglingされ、_Z6addonePfiのようになる。
(name manglingされた後の名前はコンパイルして出来たptxファイルの中身をみると分かる。)
(name mangling自体はCUDA独特なものではなくて、コンパイラと名の付くものはだいたいどれも内部で似たような処理を行っている。)
で、Driver APIを使う場合ホストコードから関数名を指定するときにname manglingされた後の名前を指定する必要があり面倒。
(この場合、元の名前を指定するとcuModuleGetFunction関数がCUDA_ERROR_NOT_FOUNDを返す)
extern “C” {}で囲めばname manglingされないのでホストコードからも元の名前で利用できて楽。
TERGETS → Build Rules → Add Build Rule
以下のような感じ。
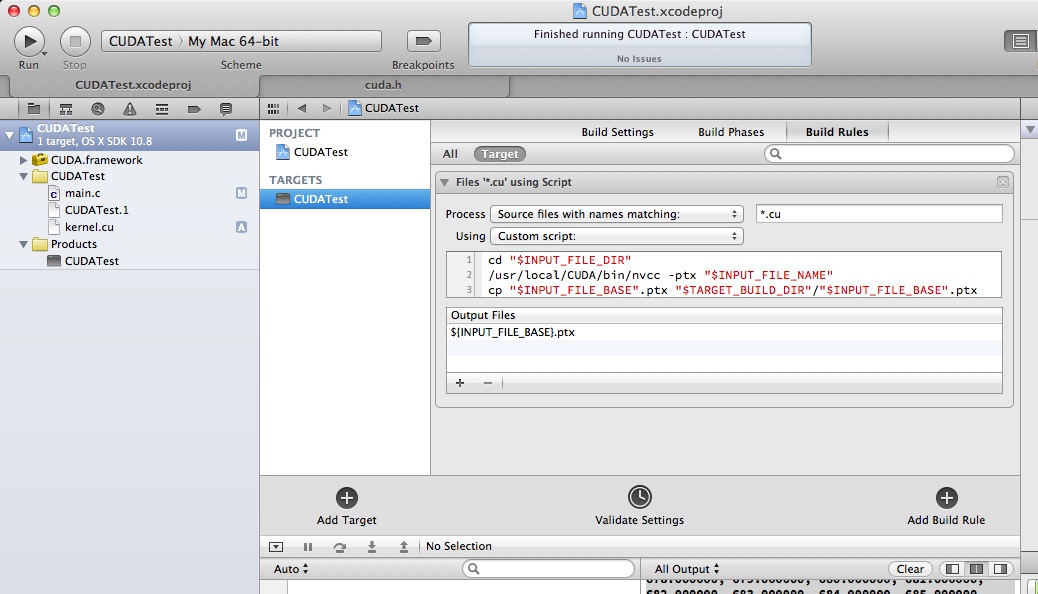
スクリプトでは、nvccでデバイスコードをコンパイルして出来たptxファイルを実行ファイルと同じディレクトリにコピーしてるだけ。
さらに TERGETS → Build Phases → Compile Souces に kernel.cu を追加。
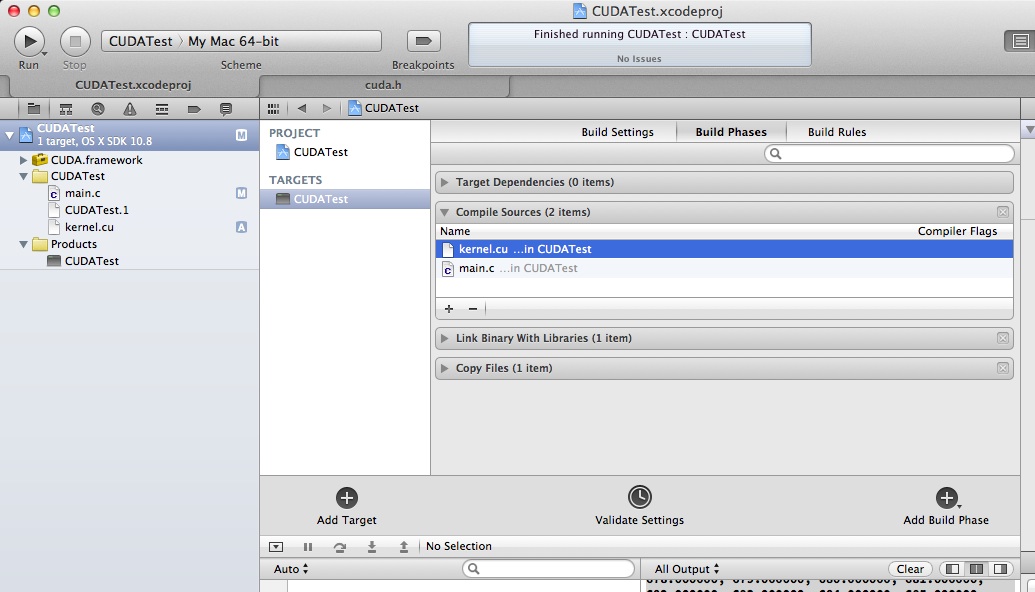
ここまで来たらあとは main.c で #include <CUDA/CUDA.h> するだけでDriver APIを使ったコードが書ける。
とりあえず今回は以下のようなコードを書いた。
処理内容としては、2 * 3 * 1 * 4 * 5 * 6 = 720要素のfloatの配列に+1.0するのみ。
初期値が0.0〜719.0なのでGPUを通した後は1.0〜720.0になるはず。
グリッドとブロックの分割がテキトーな事になってるが、通常1次元配列を操作する場合はどちらも1次元(それぞれyとzが1)にしといて、デバイスコードのインデクス計算をシンプルにすべきだろう。
CUDAの制限的にグリッドのz分割数は1固定だったと思うが今の最新GPUでもそうなのかな?
#include <stdio.h>
#include <string.h>
#include <CUDA/CUDA.h>
#ifdef DEBUG
#define EC(a, b) errorCheck(a, b)
#else
#define EC(a, b) a
#endif
typedef struct
{
unsigned int x;
unsigned int y;
unsigned int z;
} Dim3;
// cu関数の戻り値をチェックする関数
void errorCheck(CUresult result, const char *title)
{
static const char *resultStrings[] = {
[CUDA_SUCCESS] = "CUDA_SUCCESS",
[CUDA_ERROR_FILE_NOT_FOUND] = "CUDA_ERROR_FILE_NOT_FOUND",
[CUDA_ERROR_INVALID_IMAGE] = "CUDA_ERROR_INVALID_IMAGE",
[CUDA_ERROR_NOT_FOUND] = "CUDA_ERROR_NOT_FOUND",
[CUDA_ERROR_LAUNCH_TIMEOUT] = "CUDA_ERROR_LAUNCH_TIMEOUT",
[CUDA_ERROR_UNKNOWN] = "CUDA_ERROR_UNKNOWN",
};
if (result < CUDA_SUCCESS || result > CUDA_ERROR_UNKNOWN) {
printf("%s, out of CUResult renge(%d).\n", title, result);
return;
}
if (resultStrings[result]) {
printf("%s, %s\n", title, resultStrings[result]);
} else {
printf("%s, no result string.\n", title);
}
}
int main(int argc, const char * argv[])
{
// グリッドの分割数、ブロックの分割数
Dim3 gridDim, blockDim;
unsigned int threadPerBlock;
gridDim.x = 2;
gridDim.y = 3;
gridDim.z = 1;
blockDim.x = 4;
blockDim.y = 5;
blockDim.z = 6;
threadPerBlock = blockDim.x * blockDim.y * blockDim.z;
// データの要素数とサイズ
unsigned int n;
unsigned int byteCount;
n = gridDim.x * gridDim.y * gridDim.z * threadPerBlock;
byteCount = sizeof(float) * n;
// CUDAの初期化
EC(cuInit(0), "cuInit");
// CUDAサポートデバイス数のチェック
int deviceCount = 0;
EC(cuDeviceGetCount(&deviceCount), "cuDeviceGetCount");
if (deviceCount == 0) {
printf("Error: No CUDA Device.\n");
exit(0);
}
// 0番目のデバイスのハンドルを得る
CUdevice device;
EC(cuDeviceGet(&device, 0), "cuDeviceGet");
// コンテキストの作成
CUcontext context;
EC(cuCtxCreate_v2(&context, 0, device), "cuCtxCreate_v2");
// カーネルのロード
CUmodule mod;
EC(cuModuleLoad(&mod, "kernel.ptx"), "cuModuleLoad");
// カーネル関数の取得
CUfunction func;
EC(cuModuleGetFunction(&func, mod, "addone"), "cuModuleGetFunction");
// ホストメモリにデータ領域を確保
float *h_v;
h_v = (float*)malloc(byteCount);
// データの初期化
for (int i = 0; i < n; i++) {
h_v[i] = (float)i;
}
// デバイスメモリにデータ領域を確保
CUdeviceptr d_v;
EC(cuMemAlloc_v2(&d_v, byteCount), "cuMemAlloc_v2");
// ホストからデバイスへデータをコピー
EC(cuMemcpyHtoD_v2(d_v, h_v, byteCount), "cuMemcpyHtoD_v2");
// カーネルの実行
void* args[] = {&d_v, &n};
EC(cuLaunchKernel(func, gridDim.x, gridDim.y, gridDim.z, blockDim.x, blockDim.y, blockDim.z, 0, 0, args, 0), "cuLaunchKernel");
// 結果をデバイスからホストへコピー
EC(cuMemcpyDtoH_v2(h_v, d_v, byteCount), "cuMemcpyDtoH_v2");
// 結果の表示
printf("result: %d elements\n", n);
for (int i = 0; i < n; i++) {
printf("%f, ", h_v[i]);
}
printf("\n");
// ホストメモリを解放
free(h_v);
// デバイスメモリを解放
EC(cuMemFree_v2(d_v), "cuMemFree_v2");
// モジュールのアンロード
EC(cuModuleUnload(mod), "cuModuleUnload");
// コンテキストの破棄
EC(cuCtxDestroy_v2(context), "cuCtxDestroy_v2");
return 0;
}
Runtime APIを使ったコードと比べるとかなり長いが、パターンが決まってるので慣れれば難しくない。
個人的にOpenGLとかの”おまじない”の方がパターンや過去のしがらみが多くて難しく感じる。
cuInit, CUDA_SUCCESS cuDeviceGetCount, CUDA_SUCCESS cuDeviceGet, CUDA_SUCCESS cuCtxCreate_v2, CUDA_SUCCESS cuModuleLoad, CUDA_SUCCESS cuModuleGetFunction, CUDA_SUCCESS cuMemAlloc_v2, CUDA_SUCCESS cuMemcpyHtoD_v2, CUDA_SUCCESS cuLaunchKernel, CUDA_SUCCESS cuMemcpyDtoH_v2, CUDA_SUCCESS result: 720 elements 1.000000, 2.000000, 3.000000, 4.000000, 5.000000, 6.000000, 7.000000, 8.000000, 9.000000, 10.000000, 11.000000, 12.000000, 13.000000, 14.000000, 15.000000, 16.000000, 17.000000, 18.000000, 19.000000, 20.000000, 21.000000, 22.000000, 23.000000, 24.000000, 25.000000, 26.000000, 27.000000, ーーー 大胆に省略 ーーー 694.000000, 695.000000, 696.000000, 697.000000, 698.000000, 699.000000, 700.000000, 701.000000, 702.000000, 703.000000, 704.000000, 705.000000, 706.000000, 707.000000, 708.000000, 709.000000, 710.000000, 711.000000, 712.000000, 713.000000, 714.000000, 715.000000, 716.000000, 717.000000, 718.000000, 719.000000, 720.000000, cuMemFree_v2, CUDA_SUCCESS cuModuleUnload, CUDA_SUCCESS cuCtxDestroy_v2, CUDA_SUCCESS
公式のドキュメントが充実してるので引っかかったらまずはそこを見たほうがいい。
http://docs.nvidia.com/cuda/index.html
あとは効率のいいコードを書くなら、GPUの中のデータの流れが手に取るように分かるくらいになるまでGPU脳を鍛えるしかないと思う。
はじめまして。初リアルフォース(R3ですが)で,同…
ZFS poolのデバイスラベル破損で悩んていたと…
しゅごい
FYI Avoid Annoying Unexpe…
ご存じとは思いますが、whileには、”~の間”と…
[…] 花粉症対策についてはこれまで次の記事を書いてきました。https://…
[…] 花粉症対策についてはこれまで次の記事を書いてきました。https://…
[…] 花粉症対策についてはこれまで次の記事を書いてきました。https://…
[…] 花粉症対策についてはこれまで次の記事を書いてきました。https://…
[…] 花粉症対策についてはこれまで次の記事を書いてきました。https://…
© 2016 peta.okechan.net
Proudly powered by WordPress and my DIYed theme

初めまして。何とかCUDAをXcodeて使おうとしてネットを探していたら、ここにたどり着きました。
非常に助かりました。特に、nvccへの依存性を最小限に出来るのがとても有難いです。
ただ、実際に使おうとしてトラブっています。
例題をやってみると、cuMemcpyDtoHがエラーを起こします。エラーコード700でCUDA_ERROR_LAUNCH_FAILEDです。
OSは10.8.4,CUDAは最新版、Xcodeは4.6.3です。
何が悪いか心当たりがあったら教えて下さい。
よろしくお願いします。
どうも!コメントありがとうございます。
私もよく分からないですが、cuMemcpyDtoHでエラーが発生するということはそれより前の段階のcuModuleLoadやcuMemcpyHtoDなどの呼び出しではエラーが出てないという事ですよね。
通常でしたらCUDA_ERROR_LAUNCH_FAILEDはcuMemcpyDtoHの直前で呼ばれているcuLaunchKernelで起こりうるエラーですので、自分だったらcuLaunchKernelの行をコメントアウトした上で実行してみてどうなるか確認してみます。
それでも状況が変わらなければCUDAもしくはGPUドライバの不具合という可能性を考えなければならないかもしれません。
(これはあまり根拠のない主観ですが、Mac環境におけるCUDAはWindows環境やLinux環境に比べて少し不具合が多い印象があります。)